
I
guess, most of us have watched the movie "I-robot", if not please do
watch, it is indeed an awesome movie. Well what happens in that? Scientifically
it shows artificial intelligence implanted into Robots that could perform tasks
that are normally performed by human beings. Humans are often susceptible to
errors, but robots or machines aren't they do what they are asked or what they
are instructed. There may be a case in which by reiterating a process the
machine may learn from its previous experiences and start performing or
delivering with more accuracy.
Machine learning is a sub-field of Artificial
Intelligence, probably the biggest field under it.
What is machine learning?
Well, we can always refer the web to find the precise
definition of machine learning. For me, machine learning is building algorithms
that build a model (program) probably the best one by constantly learning from
the data sets. The program or model generated is then used to make prediction.
Machine learning is automating automation.
Normal programming: In normal programming systems we have inputs and we build a
program using logic and then use the program for the inputs to get the desired
results or output.

This is automating a process. You write a program once, send
inputs to it and find the output.
What if the structure of the input data is varying
constantly. We would have to write different programs for different structures
of input data, which is tedious and time consuming. So what do we do, we call
for help!
Machine Learning: Using machine learning techniques we build algorithms that takes the input and build the best program based on the input
data. This program is then used on other input data to get the output. This is
automating an automation.

The algorithm you write will automate the process of finding
different programs or models for different input stream and then use the
program that would find the output from the new input stream.
Components of Machine Learning:
Almost every machine learning
problem has three components and we will discuss them now.
Representation: Representation
is how do you represent the solution to your problem. For example suppose you
were asked to find the Fibonacci series. You would either use c or c++ or Java
or other languages to build a program that would do your task. Similarly in
machine learning we have many different approaches (Decision Tree,
Neural Networks, Naive Bayes, Support Vector Machines, Rules, Instances,
Regression) o a problem. These approaches are the representation.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Evaluation: Evaluation
can be told as the measurement of how better or accurate your approach is. You
have written a program and now you evaluate how awesome it is. For example, out
of 100 spam messages how many of the messages were declared as spam by your
program or the prediction by your program is how close to the actual output. Different evaluating models are Accuracy, Precision and
Recall, Squared error, Likelihood, Entropy, Posterior probability and others.
Optimization: We have different representations, different Evaluation
strategy for a problem and each different combination could result in n numbers
of outcomes. Optimization helps us to search the best outcome or best fit to
the problem. Optimization is the strategy that picks the best program.
Different optimizing approaches are Greedy search, Gradient descent and etc.
When combining these three
components a whole system of machine learning is developed.
A simple combination can be:
Regression (Representation)->
Squared error (Evaluation)-> Gradient descent (Optimization).
Types of Learning:
There are different types of datasets, for example, some datasets have labels, some don't and some have partial labels. There is a heavy dependency of employing an algorithm
based on the type of the data-set.
Some different types of learning are:
Supervised Learning: Supervised Learning is a type of learning in which you have supervision.
For example, you know if the message is spam or not. In
technical terms all the instances (rows) of the dataset are labeled or they have a class (output).
Unsupervised Learning: Unsupervised Learning is a type of learning where you don't have
supervision. For example, you do not know if the message is spam or not. All
you have is a set of attributes and their values. Based on the attribute value you have to segregate the spam and non-spam messages. A good example for Unsupervised
learning is server clustering. In server clustering, for each server you may have different
attributes like the RAM, CPU space, CPU load and others. There is no
specific class (output) for the input data-set. In such a case one has to group
different servers based on their similarity in space, performance, speed and
other attributes.
Semi-Supervised Learning: Semi supervised is a combination of Supervised and
Unsupervised learning. Here we have supervision on partial data-set i.e, some are labeled and
some are not. In practical applications there are many cases where 80% of the messages are not labeled as spam or not-spam. Such a scenario spawns the importance of Semi supervised learning where the messages are segregated as spam or non-spam based on the labeled data (20%) using supervised learning technique and then unsupervised learning is applied on the other data (80%). Based on their similarity with spam or non-spam messages- computed using the labeled data, the data-sets are classified into spam or not-spam.
Now let us understand each of them with layman's examples:

Lets suppose we have a data-set as given in the RHS. What do you think of the data set.
The data set can have different view.
1. One can say that column a,b,c are different attributes and d is the outcome of each instance (row).
2. One can also say that a,b,c and d are all attributes.
Intuition 1: If you see conscientiously you will see a pattern in the above data-set, which is, if you multiply 3 to each a, b and c and add them you will get d.
2*3 + 2*3 +2*3=18
3*3 + 3*3 + 3*3=27
Therefore, we can build a model and use the model on our future data set to predict the outcome. Now, if you get a new row with columns a,b and c.
Now, if you get a new row with columns a,b and c.
Now, if you get a new row with columns a,b and c.
We can easily predict d.
If the new instance is a=5, v=1 and c=3 one can perform the logic and find the outcome. i.e d= 5*3 + 1*3 +3*3= 27. Here 27 is the predicted call for the new instance.
This kind of learning is generally called Supervised learning.
Intuition 2: The above data-set also exhibits a different pattern. If you observe closely you might argue that the instances in the above data-set can be divided into even and odd rows. Where rows 1 and 4 are even and rows 2 and 3 are odd. So instead of building a pattern to calculate the d's output, we build two cluster and say if all the attributes a, b, c and d are even then they fall into the even cluster, else they fall into the odd cluster.
 For example : suppose we get a new instance as shown in the RHS.
For example : suppose we get a new instance as shown in the RHS.
Which cluster would the instance fall? Odd because all the attributes value are odd.
This kind of learning technique is called as Unsupervised Learning.
Intuition 3: Data-set can also be partial, for instance some of the data set is labeled and some aren't labeled. In such a case neither supervised or unsupervised learning would be handy.
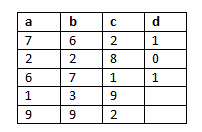 Let say we have a data-set similar to the data-set plotted in the RHS. The column d is absent for the 4th and 5th row. So how do we learn the data-set. In this case we use partially supervised and partially unsupervised learning. Looking at the data-set what pattern do you see? Can we say, If a>5, b>5 and c<5 then d=1. Similarly, If a<5, b<5 and c>5 then d=0, which is but supervised learning.
Let say we have a data-set similar to the data-set plotted in the RHS. The column d is absent for the 4th and 5th row. So how do we learn the data-set. In this case we use partially supervised and partially unsupervised learning. Looking at the data-set what pattern do you see? Can we say, If a>5, b>5 and c<5 then d=1. Similarly, If a<5, b<5 and c>5 then d=0, which is but supervised learning.  Similarly, we can group the whole data set into 2 groups.
Similarly, we can group the whole data set into 2 groups.
Group 1: a<5, b<5 and c>5
Group 2: a>5, b>5 and c<5
Based on our grouping, now we can apply unsupervised learning on the 4th and 5th row and classify (label) them as 1 and 0.
After we are done with the labeling we get the complete data set. Now we can apply whatever algorithm or learning we want to the new incoming data-set or new instances.
Thought for the Blog:
"Labeled data is scarce and expensive to obtain, whereas unlabeled data is abundant and cheap. With the shortage of labeled data enterprises are employing and building systems upon the unlabeled data to gain intelligence out of their data-set. However, it is assumed that a labeled data can give more insights than a unlabelled data.
Therefore many real world application today are heavily engaged with semi-supervised learning techniques."
In many cases the learning from both unlabelled and labelled data can result in better result in the development of better models than learning each of them separately would.